
Concurrency is when multiple jobs see incremental progress within the same time period. It may be that the concurrency is parallel where both jobs progress together at the same time or time sliced wherein parts of both jobs are done one after the other by a single processor. Whichever the case concurrency creates problems for shared resources. When there is only one job executing at a given point in time the resource can be viewed as consistent on any access. However when there is more than one job executing then care must be taken to ensure that the resource is consistent across both jobs. Consider the classic example of 2 jobs which both increment a single counter.
- Job A reads the value of the counter.
- Job B reads the same value a moment later.
- Job A writes the (value + 1) to the counter.
- Job B now writes what it believes to be (value + 1) to the counter.
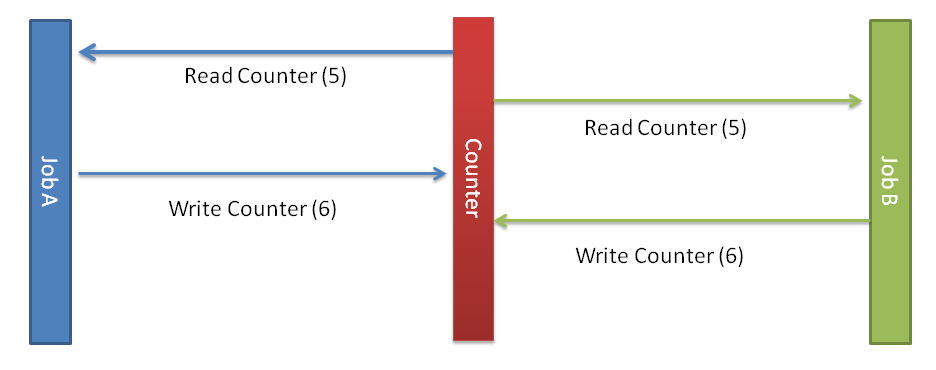
The end result is that the counter is incremented to 6 even though it should read 7. Though a simple example this succinctly demonstrates the problems associated with concurrency. With concurrent operations you must take care to give all executing jobs a globally consistent version of shared resources, but how?
Not taking the “Ignore it and it will go away” approach you are broadly left with 2 options – optimistic and pessimistic concurrency. First, lets be pessimistic and take the approach wherein Job A locks the global resource before it reads it and then updates the value. Finally after the value is updated the resource is unlocked.
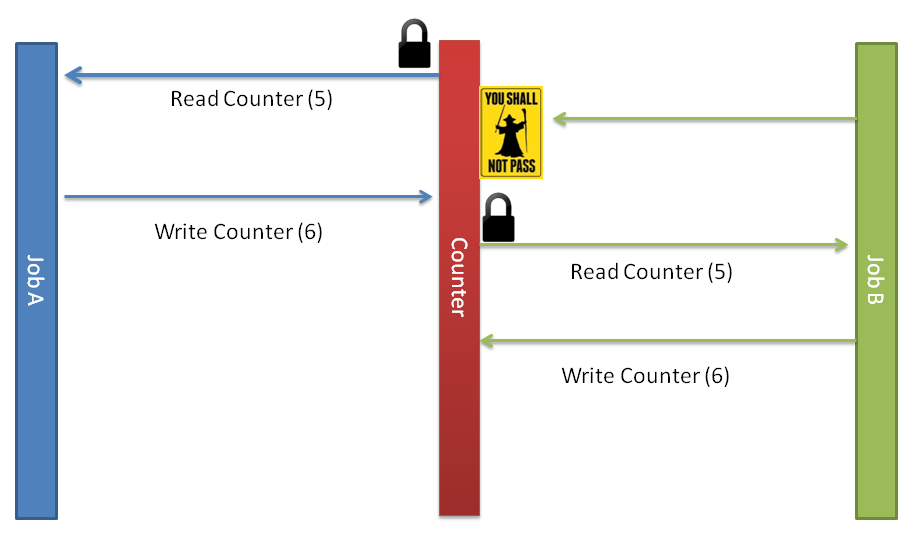
A broad reaching read/write lock like this keeps Job B from progressing solving the inconsistent state issue but introducing a bottleneck to the pipeline. Now Job B must wait for job A to complete and this means that scaling such a system becomes difficult. As more Jobs are introduced more contentions for the same resource are likely to occur.
Optimistic locking on the other hand assumes the best case, that in between a read and a write to a resource its not likely that the resource is changed by another job. However, just in case it keeps a timestamp value of the last change thereby ensuring that if in case the second job to read has an outdated value in it’s timestamp during the write it disallows that operation. The second job then has to go back to the start of the process by reading the value again and hope that it wont be beaten to the write by another job this time.
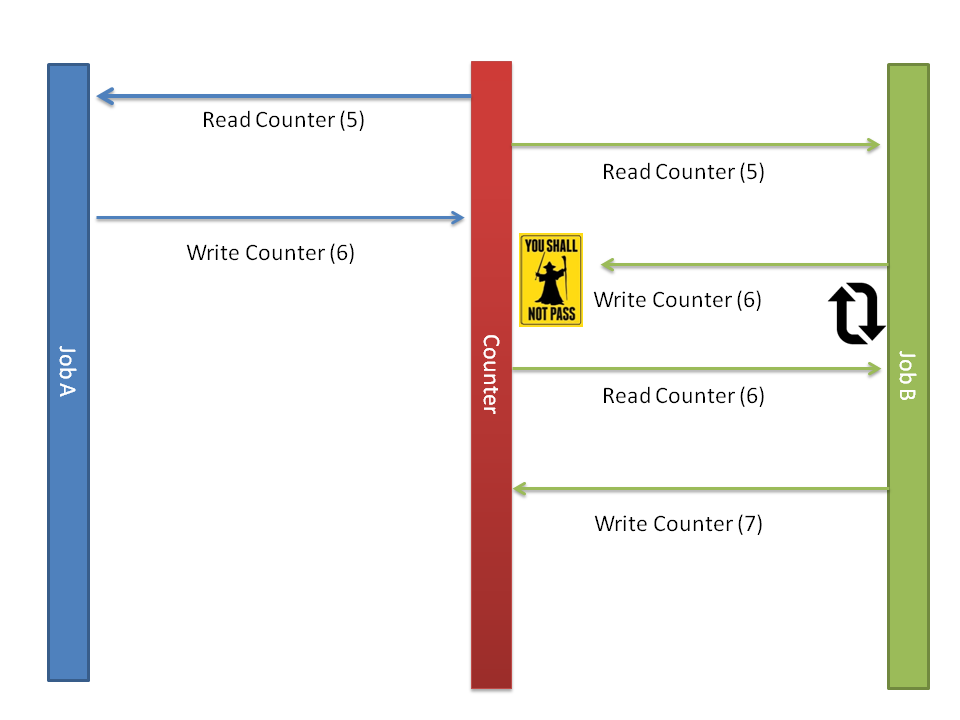
The important thing to realize here is that there is a lock involved, specifically on the write operation it must ensure that only 1 object can change the timestamp of the resource and do so atomically. This should be as close to the write operation as possible so as to avoid locking through many layers of software so that it’s a very small bit of code that actually executes fairly fast.
Typically this kind of system tends to be more easily scalable because in the real world unless your updating a single value 1000 times a second collisions are rare. On the other hand optimistic locking is mysterious, meaning that it’s hard to predict its behavior exactly because it depends a lot on the distribution of data and how much contention there actually is.