
Unicode string support in Windows is a strange beast.
When Microsoft hired Dave Cutler and others to write a new OS for them they were thinking about writing a new version of OS/2. In fact the new Microsoft OS was a combined effort by Microsoft and IBM that would have resulted in OS/2 version 3.0 if not for the success of Microsoft’s own Windows 3 which made them reconsider that approach. At the eleventh hour they shifted their API from the extended OS/2 API that was to be the way things got done on the new OS to an extended version of the Windows API. This last minute change was possible due to some clever trickery on the part of the programmers who wrote the new Windows OS but it resulted in a strange API, especially when it came to string handling in the new OS known to history as Windows NT 3.1.
Windows NT uses Unicode “internally”. This means that the operating system itself uses Unicode encoding in it’s own private functions. The Windows API as it was known in Windows 3.0 used ANSI strings, that is strings where each character was an 8 bit char. Programmes written for Window 3.0 needed to run on Windows NT so the team behind the new OS tacked on the old API as is onto NT, writing code to convert the ANSI strings used in Windows 3.0 into Unicode strings for API calls into NT and then convert them back into ANSI when returning results to the program.
For the new programs that would be written supporting Unicode they wrote duplicate functions that took Unicode strings and returned Unicode strings. As a result there is actually 2 versions of the same function in the Windows API. One that accepts ANSI strings and one the accepts Unicode strings. The hitch of course is that you can’t use both encodings as your native string encoding in the same executable. You must at compile time decide to store your characters either as 8 bit ANSI or 16 bit Unicode. Let’s take a look at how it works.
There are 2 atomic character types in Unicode Supported Windows.
| char | The good old character type. Each character is 8 bits. |
| wchar_t | The “wide” character type. Each character is 16 bits. |
char ansiString[] = "This is an ansi string.";
wchar_t UnicodeString[] = L"This is a Unicode string, Olé!";
Notice the L in front of our Unicode string literal? That’s there to tell the compiler that the said literal is a wide char literal. This means that the compiler will keep 2 bytes for each character of that string.

As mentioned before, each function is duplicated in the Windows API. One contains the ANSI implementation and the other contains the Unicode implementation. Take for instance the function’s DrawTextA and DrawTextW. Both are identical in function but one takes in ANSI strings (A) and one takes in Wide strings (W).
DrawTextA( hdc, ansiString, -1, &rect1, DT_SINGLELINE | DT_NOCLIP ) ;
DrawTextW( hdc, UnicodeString, -1, &rect2, DT_SINGLELINE | DT_NOCLIP ) ;
Here is the result:

Using an ANSI string with a W function or using a Unicode string with an A function will result in a compilation error because of the type mismatch between char and wchar_t. Checking which function to call in each case can be rather tedious so the guys who wrote NT come up with a truly cunning plan. Given a single application the common usage scenario was to stick to one single string representation be it ANSI or Unicode. The Windows API headers have been craftily crafted to allow the programmer to, for the most part, ignore the existence of the two char types.
To start with, the windows headers define a new “generic” char type called TCHAR. TCHAR’s definition can be distilled into the following bit of preprocessor code:
#ifdef UNICODE
#define TCHAR wchar_t
#else
#define TCHAR char
#endifWhat this says is that if the UNICODE preprocessor symbol is defined then every mention of the text TCHAR is replaced by wchar_t by the preprocessor, whereas if UNICODE is not defined it’s replaced with char. Practically this means that you can define a single string like this:
TCHAR anyString[] = TEXT("This can either Unicode or ansi. Olé!");
TCHAR will be replaced by either char or wchar_t depending on the definition of the UNICODE symbol. Similarly the TEXT macro will either be replaced by L (for Unicode) or nothing (for ANSI) using the same kind of preprocessor magic that powers TCHAR. Where is the Unicode symbol defined? Where indeed…
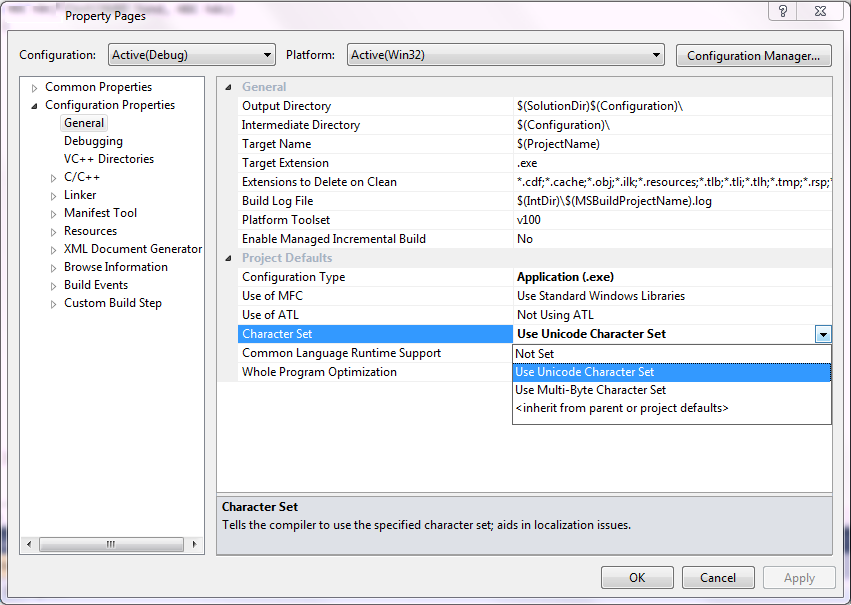
That option results in the _UNICODE and UNICODE preprocessor symbols like so:
/ZI /nologo /W3 /WX- /Od /Oy- /D "WIN32" /D "_DEBUG" /D "_WINDOWS" /D "_UNICODE" /D "UNICODE" /Gm /EHsc /RTC1 /GS /fp:precise /Zc:wchar_t /Zc:forScope /Yu"StdAfx.h" /Fp"Debug\UnicodeAndAnsi.pch" /Fa"Debug\" /Fo"Debug\" /Fd"Debug\vc100.pdb" /Gd /analyze- /errorReport:queueSelecting the “Multibyte Character Set” option will result in the UNICODE preprocessor symbol not being defined and TCHAR will suddenly get neutered to char.
Finally each pair of functions in the windows API is replaced by another UNICODE symbol dependent definition. For example the DrawTextW and DrawTextA functions are amalgamated into a single DrawText function using the following definition.
#ifdef UNICODE
#define DrawText DrawTextW
#else
#define DrawText DrawTextA
#endifNotice the similarity to the definition of TCHAR (and the TEXT macro)? This makes life much easier. We can now just define a string as an array of TCHAR characters and use the generic Windows API function names to do stuff with those strings like so:
TCHAR anyString[] = TEXT("This can either Unicode or ansi. But α and ω needs Unicode.");
DrawText( hdc, anyString, -1, &rect3, DT_SINGLELINE | DT_NOCLIP );If you compile this program using the Unicode Character set as described before you get the following output with all text rendering correctly.

However if you compile the program using the Multi Byte Character set (ANSI) the characters that require Unicode encoding do not render properly and you end up with the infamous “?” characters.

Which goes to show that even though you can now fairly easily convert a well written Unicode program into an ANSI one you have to ensure that the text that you allow into your program fits into the character set that it’s being compiled into.
I should mention in passing that the windows headers define a plethora of other string type like LPSTR, LPWSTR, LPTSTR, LPCTSTR etc. These are all sorts of combinations of pointers to char or wchar_t or TCHAR. Don’t be intimidated by their complex appearance, a look at their definitions should make their meaning relatively simple.
There you have it, Unicode on Windows.